Context Window to full extent
Every large language model has a context window, the finite stretch of text it can “see” at any particular time. Your prompt, conversation history, system instructions, or documents, all lies inside that window and shapes the next output token. Everything outside it might as well not exist.
For years, this window was painfully small, while the increase in context window sounds revolutionary, but they only delay the bottleneck, not remove it.
With such huge windows, why even bother?
Even when all the necessary information still lies within the window, the model can degrade, producing inconsistent or even hallucinated responses, this is because models have "attention budget" which they process at once when parsing large amount of data. Every new token introduced depletes this budget by some amount, increasing the need to carefully curate the tokens available to the LLM.

For example, while using response_format as JSON, you might explicitly instruct the model to reply in JSON. Yet, if you omit the word “JSON” in a later prompt — even though that instruction is technically still within the window — the model may fall back to plain text. Models with million-token windows like Gemini 1.5 Pro and Claude 3 Opus exhibit instruction loss mid-context, requiring explicit reinforcement of critical directives (e.g., repeating “Respond strictly in JSON” at each turn).
This illustrates a subtle but crucial point: the model doesn't truly “recall” — it only reweighs attention across visible tokens. And that limitation defines the boundary of what your Agent can do.
As your AI agent iterates through its reasoning loop, it accumulates an expanding set of potentially relevant data (state updates, retrieved facts, user inputs, and generated hypotheses) for the next turns. Since the model's context window is finite, this data cannot stay in the window all at once, we must define systems to selectely reintroduce this data when the LLM needs it.
This selective process is known as context engineering: the systematic curation of information that enters the model's active context to maximize coherence and efficiency.
Understanding what a good context means?
A good context is not just everything that's relevant — it's the minimal, well-structured subset of information that maximizes the model's ability to stay coherent, factual, and task-aligned. Think of it as attention economy management. Every token competes for a limited share of the model's limited attention budget. A good context ensures that the right tokens win that competition.
Anthropic recommends organizing prompts into distinct sections (like background_information, instructions, ## Tool guidance, ## Output description, etc) and using techniques like XML tagging or Markdown headers to delineate these sections.
The goal isn't to remind the model of everything, but to equip it with just enough to act intelligently in the moment. A well-engineered context is lean yet expressive: it captures the user's intent, reinforces critical rules, and surfaces only the most relevant past information or retrieved facts.
A good context is deliberate, not accidental — but keeping it that way gets harder as conversations grow. To manage this, we need techniques that actively decide what to keep, what to drop, and what to retrieve when needed. This is where methods like Context Compactation, RAG, Memory files, and Sub-agent architectures come into play.
Retrieval Augmented Generation
RAG is a very vast topic, and can be traced all over the AI application layer. Code agents are some of the best examples of RAG in large-scale production.
In agentic systems, RAG offers a powerful way to make reasoning loops more efficient. Rather than forcing the model to regenerate or reprocess information each time, RAG can be utilised to cache subqueries. When a similar query appears again, instead of asking the LLM to rebuild the plan from scratch, the system can retrieve prior results from a vector store. These stored results act like reusable knowledge blocks, ready to plug back into the reasoning chain whenever needed. This not only saves time but also reduces cost, since every avoided LLM call trims both latency and token usage. What makes this approach especially elegant is that it redefines what “context” means. Context isn't just a static window of past tokens; it's a dynamic resource, something that can be searched, filtered, and reused based on similarity and intent.
RAG can also be extended beyond data retrieval into tool selection. When an agent is given too many tools often with overlapping or ambiguous descriptions, it can become uncertain about which one to use. By applying RAG here, the system retrieves only the most semantically relevant tools for the task at hand. The paper Toolshed: Scale Tool-Equipped Agents.. showcases how this simple step can improve tool selection accuracy by up to threefold.
Compaction
Context compaction is the practice of summarizing accumulated interactions and reinitializing a new, lighter context window seeded with that summary. Instead of endlessly expanding the context, compaction distills what's already there, preserving key goals, facts, and reasoning steps while reducing token load.
Think of it like playing Minecraft. As you roam the world searching for a llama, you pass through forests, rivers, and villages. Once you finally reach the desert, you don't consciously remember every single block you walked past. Instead, your brain keeps a compact summary: “You're in the desert, looking for a llama, last spotted near the dunes.” That's compaction in spirit: forgetting irrelevant details while keeping a coherent mental snapshot that lets you keep progressing toward your goal.
Systems like Claude Code use a similar mechanism called “auto-compact,” automatically summarizing interactions once the context nears its limit. These summaries can follow recursive or hierarchical strategies to maintain fidelity across long trajectories. Compaction can also be applied at more granular levels, such as summarizing token-heavy tool outputs or compressing information at agent agent boundaries to reduce transfer overhead.
The art of compaction lies in deciding what to keep versus what to discard. Compress too lightly, and the model wastes tokens on noise; too aggressively, and you risk erasing subtle details that only prove important later. Engineers designing compaction systems often tune prompts iteratively: start by maximizing recall and capturing every potentially relevant detail,then refine for precision by trimming superfluous content.
Structured note-taking / Memory files
Structed note taking, is a technique where the agent regularly writes notes persisted to memory outside of the context window. These memory files can be tool call results, a mega plan which the agent have to follow, or any kind of fact or information the agent might need in future and can be pulled anytime.
Imagine you're playing Minecraft again on your quest to find a llama, but also to build a base, and craft a saddle. Along the way, you keep a notebook: where you last saw llamas, coordinates of useful villages, and which materials you still need. You don't carry all those details in your head (your “context”); instead, you've written them down so you can check them anytime. That notebook is your memory file—structured, persistent, and evolving with each step of your journey.
For an AI agent, the same principle applies. Instead of retaining every interaction or computation inside its prompt, it stores distilled, structured notes—like JSON records, key-value pairs, or summaries—into external memory. Later, when the agent needs that information, it can retrieve and reintroduce it selectively. This allows for scalable reasoning across long tasks, continuous improvement, and resilience even when the raw context is reset.
Sub-agent architectures
Sub-agent architectures solve the context build up by dividing one large, monolithic agent into specialized smaller agents. Each with its own context, prompt, and area of responsibility.
Imagine an customer support agent that handles everything from returns and warranties to billing inquiries. If a single agent tried to juggle all of that, its context would quickly become bloated with conflicting instructions — details about refund policies, warranty timelines, and invoice generation competing for attention. The model's focus would blur, and even simple queries might produce inconsistent or incorrect responses.
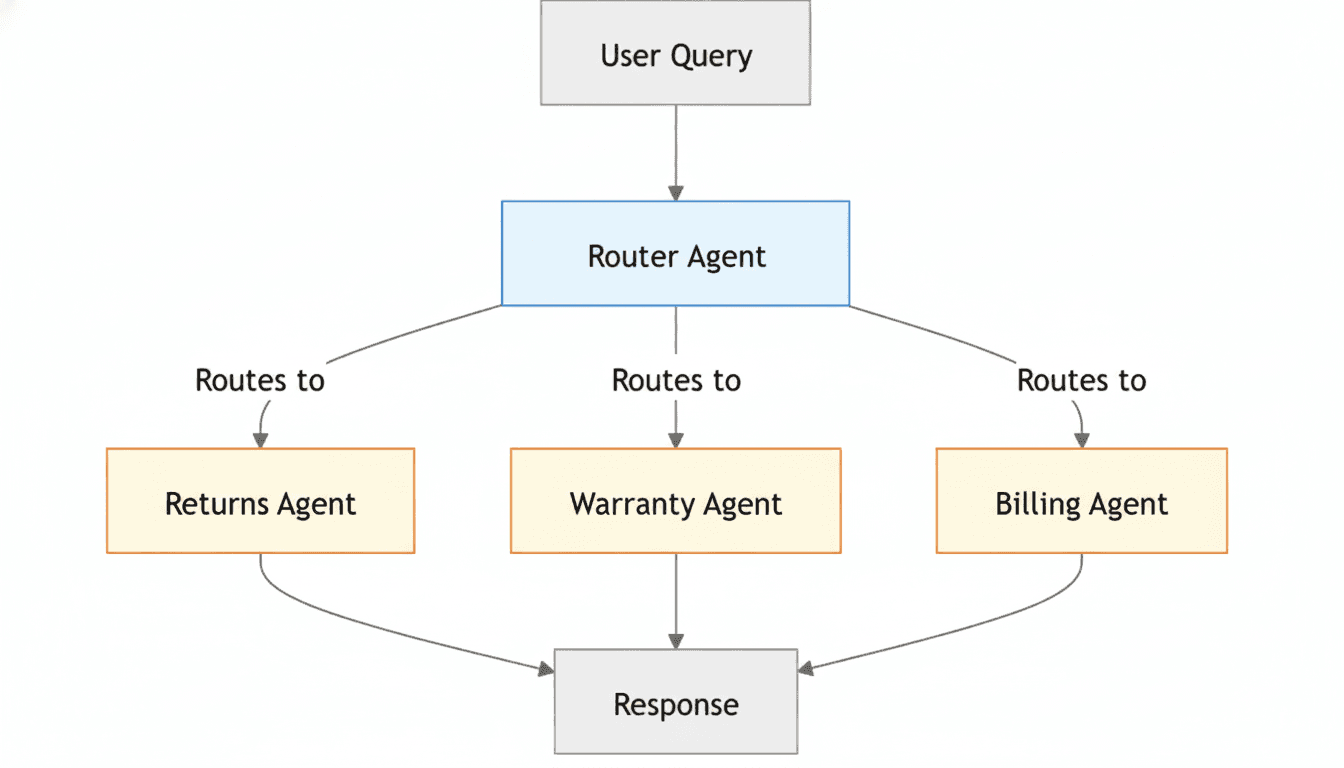
By splitting this system into specialized sub-agents — a Return Agent, Warranty Agent, and Billing Agent — each operates within a compact, well-defined context. The Return Agent only needs return policies and workflows; the Warranty Agent handles product coverage and repair rules; the Billing Agent focuses solely on payment history and invoices. The main customer support agent agent simply routes the query to the right specialist and aggregates the responses.
This architecture dramatically reduces context overload, improves accuracy, and allows each sub-agent to evolve independently. Instead of one overworked generalist, you get a team of focused experts — each efficient in its own domain, yet coordinated toward the same goal.
Conclusion
Designing effective agentic systems is as much about managing context as it is about reasoning or tool use. Techniques like RAG, context compaction, structured note-taking, and sub-agent architectures all tackle the same core challenge: helping the agent focus on what truly matters while avoiding overload. RAG teaches the value of retrieving relevant information dynamically, compaction distills ongoing interactions without losing coherence, structured note-taking builds persistent memory for long-term goals, and sub-agent architectures divide responsibilities to maintain clarity and precision.
Together, these strategies form a toolkit for scalable, reliable, and efficient agents. They allow agents to handle long conversations, complex workflows, and multiple tools without getting bogged down by their own history. At its heart, context engineering is about balance—deciding what to remember, what to retrieve, and what to hand off. Mastering this balance is what transforms a capable AI model into a truly effective, agentic system.